There are fads and fashions in finance and business. Some statistical techniques come and go in and out of favor based on expectations of success and the realization that some tools just cannot solve certain problems. Data mining in now a hot topic in many areas of business, yet there are not clear definitions of what data mining means, what tools it represents, and how it can solve problems. Clearly, the low cost of computing and storage has made the collection of data much easier, but the problem is not with the data. The issue is how you extract the data “ore”, how it is processed, and what you do with it once it is modeled.
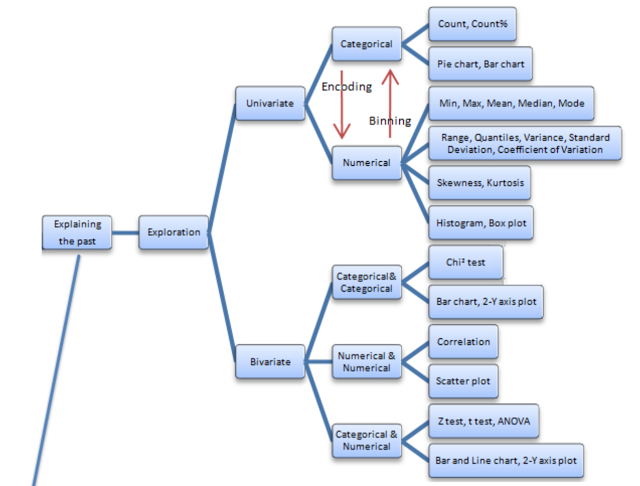
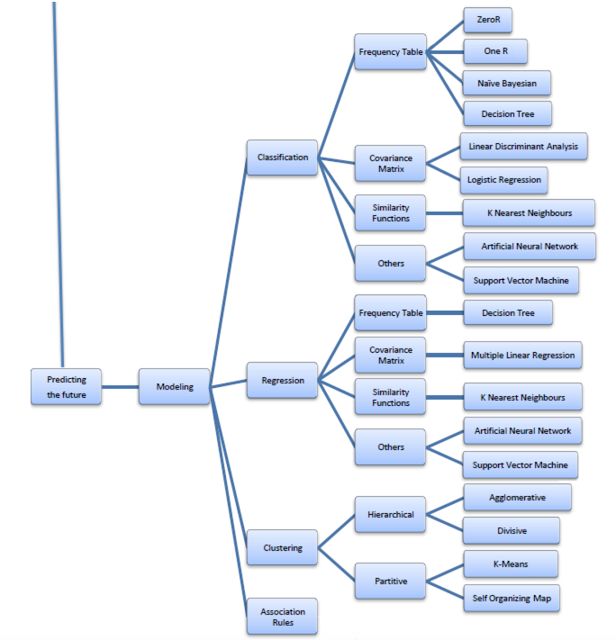
I don’t have all of the answers and am still learning, but the graph below was helpful at presenting the rich and diverse set of tools that can be applied to large data sets. Data mining can be broken into two parts: one, explaining the past and two, modeling or predicting the future. The explaining of the past can be viewed as a problem of data reduction. How can you take a large data set and categorize it into smaller more meaningful chunks of information. The second part is taking the data and making inferences that can be applied to future behavior. You cannot do the second without extensive work on the first.
The problem with data mining is that with so many tools for explaining the past and predicting the future it is not clear what is the right tool for the right problem. For example, is regression always the best tool or would techniques of classification and clustering better solve the problem. Mining is complex and a first order problem is finding the right tools to match the data.