
“An algorithm could really do better than humans because it filters out noise. If you present an algorithm with the same problem twice, you’ll get the same output. That’s just not true of people.”
“But humans are not very good at integrating information in a reliable and robust way. And that’s what algorithms are designed to do.”
– Daniel Kahneman interview “Where Humans Meet Machines: Intuition, Expertise, and Learning” MIT IDE
In a recent interview, Dan Kahneman talks about the problem of decision noise. When a group of decision-makers are given the same set of repeatable tasks or problems, you would like for them to generate the same answer, yet that is not the case. There is limited consistency with decision-making.
Kahneman discusses a research test done with a set of insurance underwriters who are given six sample problems. He believed that there was a surprising amount of noise given the controlled experiment with disagreement about 56% of the time. Professionals with the same training and facing the same stylized problem should generate the same answer. That is not the case.
Investors may face the same problem. There seems to be a significant amount of noise around decisions that are facing similar sets of facts. Take any economic announcement as a simple case. There is a significant amount of trading volume and thus disagreement on how to interpret the new facts. Perhaps investors always think this time is different. More precisely, investors may be using different models or have different beliefs that will lead to different conclusions. Reality is only revealed later. This may not be a bias but just dispersion around reality. Investors may be facing too much information that creates a situation for decision noise to exist, (see Pump down the noise – Decision silence).
An algorithm will allow for similar reactions to a repeatable set of facts. There will still be errors but a repeatable process will shrink the noise and allow for feedback on what may have gone wrong. Ending randomness with decision-making is a positive that can be achieved through using models.
Related Posts
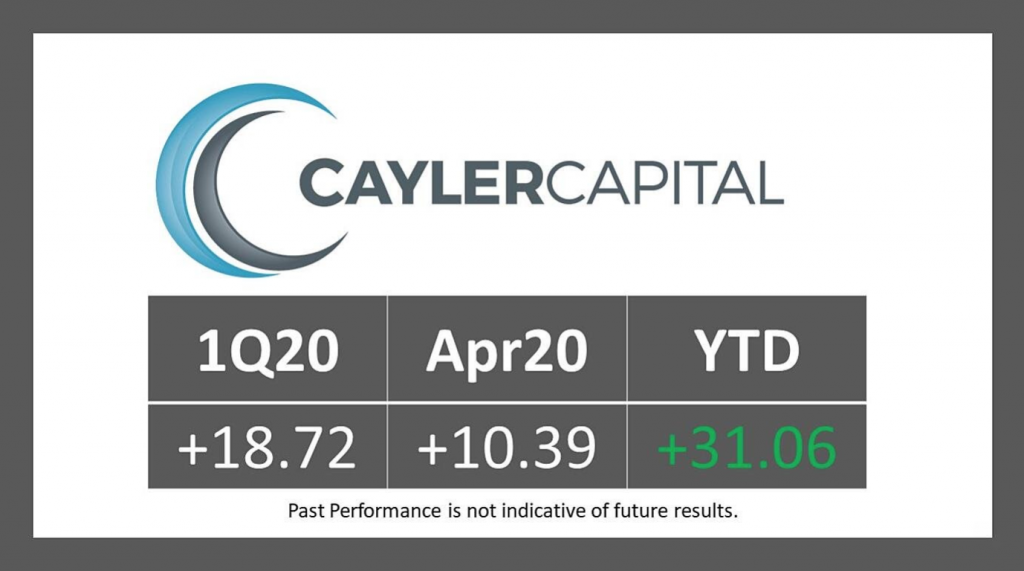
Cayler Capital | April Performance Commentary
After finishing off one of the wildest quarters of my trading career, April managed to take the cake. For those that missed it (not sure how you possibly could have), oil settled negative $37. The effects of this were immediate: risk barometers had to be recalculated, option models switched, and most importantly was the immediate […]

Mike Lombardi, football coaching and investing
I am not a football fanatic, but I picked up this book on a recommendation and was amazed by Lombardi’s insights on leadership and management. Mike Lombardi is long-time football executive and media analyst. The book focuses on Bill Belichick and the New England Patriots, but his conclusions could apply to any money management firm. A good money management firm is successful because it acts like a well-disciplined organization with a common purpose. That is no different than a competitively run sports organization. Lombardi finishes his book with five key recommendations for firm success that are worth presenting in bold.
“The Emeril Lagasse Theory” – Practical knowledge and culture is not often transferable
After hundreds of discussions with hedge fund managers, I am still surprised that there is a fear of revealing investment processes under the assumption that someone will steal their ideas and intellectual capital. There are few investment styles that are truly unique and special. What is special is still strategy execution – the practical process of delivering returns. Skill is with the decision-making execution of information and strategy.